



How do we build better machine learning model architectures? How can we obtain stronger theoretical guarantees, and develop models that generalise and extrapolate more reliably? How can we use research results to have an impact in real industrial systems? And why is the path from a published method to a reliable deployment so much longer than most people expect?
This was among the topics when top researchers from, among others, University of Cambridge, ETH Zurich, EPFL, Politecnico di Milano, University of Pennsylvania, Autodesk, NVIDIA, and Google DeepMind presented their work on machine learning grounded in physical principles. They met in the bi-annual PhysML workshop, hosted by SINTEF in Hurdalssjøen, close to Oslo.
The three-day workshop evolves around presentations and discussions on scientific machine learning, with a particular focus on physics-informed and structure-preserving methods. In this blogpost, we will summarize some of the key findings and discussions that touches upon the use of AI today, how it can be better integrated with the industry and some key learning from examples that are already implemented.
Six principles from industrial machine learning
For researchers considering industrial applications of their methods, and for industry practitioners considering academic collaboration, they point to six principles that have held up:
- Start with the decision, not the model. Understand what choice needs to change, and work backwards. Talk to stakeholders early. It is their process that will change when the model will be operational.
- Measure value, not just accuracy. A model that improves a decision may be less accurate on average but better near the thresholds that matter. Define what success looks like before building anything.
- Prefer boring models when sufficient. Small, inspectable, maintainable models often survive industrial reality better than large general ones.
- Use structure where it changes the decision. Physics, geometry, causality, and constraints are biases — use them when they encode decision-relevant knowledge that the data alone cannot provide.
- Design for uncertainty and change. Confident AI is easy to build. Useful uncertainty is difficult. Industrial systems drift; the model must fail visibly, adapt carefully, and be monitored continuously.
- Treat adoption as part of the system. A model that the organisation cannot understand, trust, maintain, or act on is not deployed technology. It is a prototype. Useful industrial ML systems know what decision they serve, what knowledge they rely on, when they are uncertain, and which humans and organisations will live with their consequences.
The gap between methods and deployment
In 2025 McKinsey stated that 88% of companies use AI in at least one business area. It’s a number worth a second look, as broad adoption does not necessarily mean that AI is being used to model the physical processes on which industrial decisions depend. This is supported by a Gallup survey of U.S. employees where only 9% reported using AI to make predictions, and 8% to set up, operate, or monitor complex equipment. The more common uses were chatbots and virtual assistants (61%), for consolidating information, generating ideas, learning new things, and automating basic tasks.
In other words, much of today’s workplace AI usage is an individual productivity layer, not models that support engineering decisions or help run physical systems. This explains why AI can seem widespread while still having limited impact on industrial decision-making.
Engineering models affect systems where mistakes are costly. Reducing delays in public transportation, making better use of hospital resources, and balancing fluctuating wind power on the electricity grid all require more than plausible predictions. They require models whose behaviour can be trusted when conditions change, data are scarce, or decisions move close to operational limits.
Physics-informed and structure-preserving methods are being developed in response to these challenges. A purely data-driven model can produce output that violates physical laws, and it tends to become unreliable when it is used in conditions unlike those it learned from. While these methods may help with industrial implementation, alone they are not enough, and they have not yet revolutionised industry.
Industrial reality is hard
The first collision with reality for applying machine learning in industry is the data, which are often very different from the nicely curated datasets used for benchmarking models in research papers.
Industrial systems are complex, built up over time, and not typically designed with data collection in mind. Sensors are sparse or non-existent; you may rely on manual measurements or infer what you cannot directly observe. The data that does exist is often noisy and drifting, and they may not be labelled.
The time series are long, irregular, and much harder to interpret intuitively than images or text. And often you cannot even measure the quantity you actually care about: If the inside of your aluminium furnace is hot enough to melt aluminium, it is also hot enough to melt any thermometer you put in there.

When data is challenging, it is tempting to use simulated data instead. Simulators give control and allow generating edge cases and high-resolution data on demand. The difficulty is that simulators rarely capture the full complexity of the real system. Industrial data can do that, but it is usually collected under normal operation, with limited variation and few rare events.
A structured model can still be wrong
The noise is also different from the neat assumptions we often make in research. We may test models with Gaussian noise because it is mathematically convenient, while real sensors can have bias, delays, calibration errors, missing values, outliers, and artefacts from the control system. Machine learning models can learn artefacts in the data instead of the underlying signal.
Adding physics to the loss (physics-informed neural networks, PINNs) may help some cases, but it may also create more trouble: The model is asked to fit imperfect measurements while also satisfying an idealised physical equation — hence if these two objectives pull in different directions, training can become unstable. Even when the two terms are in agreement, their different adaptation rates may lead to numerical instabilities which are amplified by noisy data. So while PINNs are intuitively attractive, the broader family of physics-informed and structure-preserving methods has a stronger argument to make: by imposing that a model respects certain physical laws, we can restrict how the model can fail, regardless of the training data.
That matters because safety-critical requirements change what good enough means.
In energy, maritime, and process industries, a wrong prediction at the wrong moment is more than a missed KPI; it can damage equipment, disrupt service, or contribute to a dangerous situation. A structured model can still be wrong, but its failure modes can be made more controlled.
Good decisions require more than believable predictions
Machine learning has become remarkably good at finding patterns in data. What we need to become better at is asking the right questions and building purpose-driven models.
Consider power transformers, the critical assets in the energy grid that ensure stable voltage delivery. Their lifetime is closely tied to temperature: as a transformer heats up, the insulation around its windings ages faster, eventually reducing its ability to operate safely. Grid operators, therefore, keep transformers well below their thermal limits, using large safety margins to protect assets that are expensive, critical, and difficult to replace. Data-driven models can predict temperature as a function of transmitted power; however, most grid operators cannot take the risk to collect data above that conservative threshold. The resulting model is therefore trained on data collected entirely within the safe operating regime, which means it will either always predict temperatures safely below the threshold, which is of little operational value, or extrapolate into a regime where its predictions cannot be trusted.
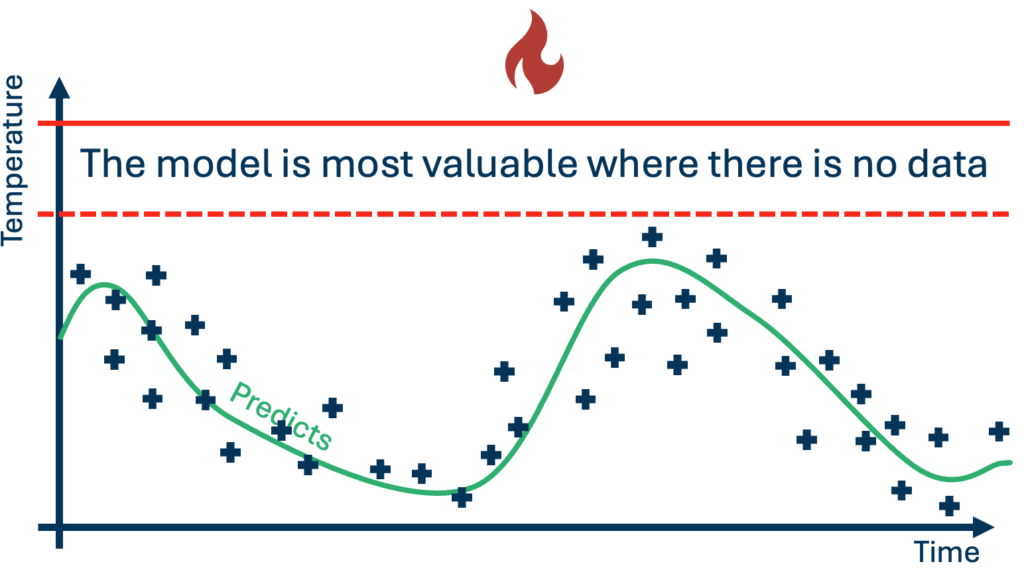
This pattern is common in industry. Data is abundant during normal operation, while the value often lies near thresholds, constraints, and rare failure modes. A model may accurately capture historical trends and still give little support for the decision that matters.
Good industrial models are designed for the decision they support and informed by relevant data and knowledge.
Brunvoll case: Prefer boring models when they are sufficient
We also need to accept that most industrial machine learning is unglamorous. The best industrial ML is often the kind you do not notice because it sits quietly and repeats the same task again and again without any fuzz.
Brunvoll, a Norwegian manufacturer of ship thrusters, wanted to monitor the condition of their units installed on vessels around the world. Flying mechanics to service thrusters on the other side of the globe is expensive; so is an unexpected failure. The critical variable for thruster health is lubrication oil level, but the raw signal is almost impossible to work with: pressure, temperature, and ship movement make it jump around constantly, and operators add oil whenever they think it is needed, introducing irregular step changes.
We tried a range of models to extract the underlying oil-level trend — and none outperformed linear regression over short intervals. That is what Brunvoll operationalised together with a couple of other more complicated algorithms. No deep learning. No foundation model. Just a robust model that changed maintenance decisions because it was simple, adaptable to each individual thruster, and scalable to a global fleet.
The principle: prefer boring models when they are sufficient. Reserve the complexity of physics-informed or structure-preserving methods for problems where that structure genuinely changes the answer — where extrapolation beyond training data matters, where physical constraints are safety-critical, or where physical interpretability is required.
Veas case: A model trained before a process change is of no use
One of the most persistent challenges in industrial settings begins after deployment, as the model needs to stay reliable even though the operational environment may be changing over time.
Veas, responsible for treating half of Oslo’s wastewater, uses a biological process to reduce nitrogen. Bacteria are fed methanol, a major cost driver in the process, and better dosage decisions would both reduce cost and ensure the water stays clean. But the biological process is sensitive to weather, season, and the composition of incoming water. A model trained in summer performs differently in winter. A model trained before a process change describes a system that no longer exists.

We developed an approach where the model learns patterns on short timescales and forms a linear combination of them, periodically expanding the pattern library with new behaviour. That is appropriate for this application and will be tested at the Veas pilot plant in Autumn 2026.
After deployment, the deeper challenge is deciding when and how a model should change. A drop in performance can have several causes: there may be sensor drift or calibration issues, the operating conditions may be different, or the data being collected may no longer reflect the same situation.
We never observe the true physics, only the data; physical models are what let us interpret what is changing and why.
In some industrial settings, we have gone further: using existing physics-based simulators as the backbone of the model rather than trying to replace them. In work with Cognite and Kongsberg Digital (now Falkor) on industrial maintenance decisions, we used simulation-based inference to infer latent variables — hidden degradation states — from a complex simulator of an oil platform. Instead of running Monte Carlo Markov Chain (MCMC), which is intractable for large simulators, simulation-based inference learns the likelihood distribution directly, making it possible to recover the full posterior over hidden states (as opposed to Gaussian estimates from Kalman filters).
The simulators already exist, are already trusted, and are already good. The value is in using them to answer questions they were not originally designed to answer.
An accurate model is not always the same as a useful model
Another underappreciated problem is simply measuring the impact of the model. Machine learning model performance is often measured in accuracy. But an accurate model is not the same as a useful model. The useful model is the one where we can show that it improves a decision.
For wastewater treatment, it is tempting to compare methanol usage before and after. But methanol consumption also depends on weather, seasonal variation, and the composition of incoming water.
You cannot just compare to a random baseline period. Defining a rigorous evaluation requires the same care as designing the model, and the cost of development, implementation, and maintenance has to be weighed against the savings. The impact will be very case dependent and requires understanding the operational reality of the model and the stakeholders.
The hardest part of industrial AI is often not improving the model
When you have a good model and a clear measure of success, the hardest challenge is still ahead: getting the model adopted by the users.
Adoption has several layers. People need to trust that the model is sound, understand what role it plays, and see how its output helps them make a decision.
In a project on logistics for road construction, we built a tool that gave site managers an overview of truck flows and could explain the source of each delay. We gave a careful explanation of how the algorithm worked. The managers asked good questions. And at the end, their main feedback was: “You do not need to show all the explanations. Could you just make the curve red when there is a delay?”

We had assumed that explanations would build confidence that the tool was useful. The site managers brought us back to the job they had to do: notice delays quickly and decide what to do next. A red curve was more useful than a detailed explanation because it fit their workflow.
Improving model accuracy from 92 to 93 percent is often easier than reorganising a workflow so that people actually act on model outputs. We can tune hyperparameters, add an agentic interface, or set up technical safety guardrails. But the human challenges, such as workflow, incentives, trust, responsibility, are less visible and more resistant to technical solutions.
As we concluded our workshop, we got a reminder to why this work is worth doing. The methods being developed address real limitations of standard machine learning in physical systems.
The theory is advancing, and some of it will genuinely matter in industry. The hardest part of industrial AI is often not improving the model. It is changing the decision process the model has to enter.

AI @ SINTEF
Analytics and Artificial Intelligence
SINTEF has expertise within AI for physical processes and industrial systems, focusing on finding the best AI solutions for the industry and the public sector. We research and develop robust, explainable, and knowledge-informed AI methods to improve decision making in challenging real-world systems.










Comments
No comments yet. Be the first to comment!