

Market analysis suggests that only 20% of AI aware companies are using some form of AI technology in their operations . A key challenge reported by many organizations is the difficulty of integrating experimental results into established business processes due to technical and organizational challenges. This affects both internal and external experimental projects. After all, why commit millions to (successful) experiments if no framework for operationalizing results and exploiting savings exists?
In this blog post, we recommend a framework for identifying processes to benefit from AI, develop and iterate on prototypes, and finally deploy them into production. We then present a few technical solutions that can accelerate experimental work and deployment of results into the organization. We will not address organizational challenges, but refer to McKinsey & Company for an in-depth survey.
The Framework
Work is broadly split into three phases.
- First, stakeholders (e.g., operators, planning experts, researchers) and data scientists run workshops to generate ideas on how data-driven solutions can address (i) serious pain-points and (ii) low-hanging fruits. Particularly for initial projects, low-hanging fruits are preferable. Data scientist then iterate solutions and evaluate them against pre-determined performance metrics.
- Once a model passes acceptance thresholds, a cycle of improvement and model deployment begins. Data scientist run experiments to improve model performance. At the same time, models are deployed so they can be integrated into processes. If better performing models become available, they will automatically be served. Deployed models must be monitored for performance. This is called MLOps (Machine Learning Operations), AIOps (Artificial Intelligence Operations), or DevOps (Development Operations).
- Finally, deployed models must be integrated with data ingestion and processing pipelines. They need to run predictions on live data and be improved by integrating newly archived data.
The illustration below shows typical activities and software for the phases in slightly more detail. Some inspiration was taken from the ProductionML value chain described here.

Business Drivers. Bring together internal and external stakeholders with data scientists. Generate ideas about processes that can be improved with data-driven insights. Set performance indicators and requirements so that results can be decision gated. Facilitated by frameworks such as Design Thinking, 10 Types of Innovation, or types of Business Process Analysis (LEAN, Six Sigma).
Data Science. Prepare, process, and analyze data to assess validity of ideas generated together with business stakeholders. Log and document experiments and keep stakeholders updated using performance indicators. This is a heavily iterative process as hypotheses become invalidated, are adjusted, and finally validated. Coding languages: Python, R, and Julia.
Model Versioning. For successful applications, iteratively improve models by model tuning, feature engineering, and addition of new data sources. Track and archive model versions and associated training data (data provenance). This ensures reproducibility and enables automated rollout (and rollback) when models improve (or fail).
Model Deployment. Make models available for integration into new and existing workflows. Serve models through APIs, so they are agnostic to to existing infrastructure. Automate rollout/rollback through by continuous integration and deployment (CI/CD) with performance monitoring. This ensures that best performing models are automatically deployed and that misbehaving models are rolled back. Tools and frameworks: Spark, Docker, Kubernetes.
Data Pipelines. To exploit operational models, build robust data ingestion pipelines. This enables real- and near-time processing and continuous improvement of models. Archive all inbound data to allow data scientists and business stakeholders to develop new and iterate on existing improvements. Tools and frameworks: Kafka, MQTT, Avro, Thrift.
Tools to Accelerate Time-To-Deployment
By now, most data scientists in organizations (and research as well as consulting services) have selected their data science tools. As such, we now focus on tools to accelerate experiments and organizational deployment. There exists a large array of commercial and open-source solutions that can address some these aspects. We have chosen to describe four representative solutions, and also present a list of commercial one-stop-shop alternatives that can be evaluated once AI adoption within the organization matures.
Finally, we will give concrete technical recommendations for organizations that consider their stage in the AI journey.
NeptuneAI
NeptuneAI is a tracker for experiments with focus on Python. It is a hosted service.
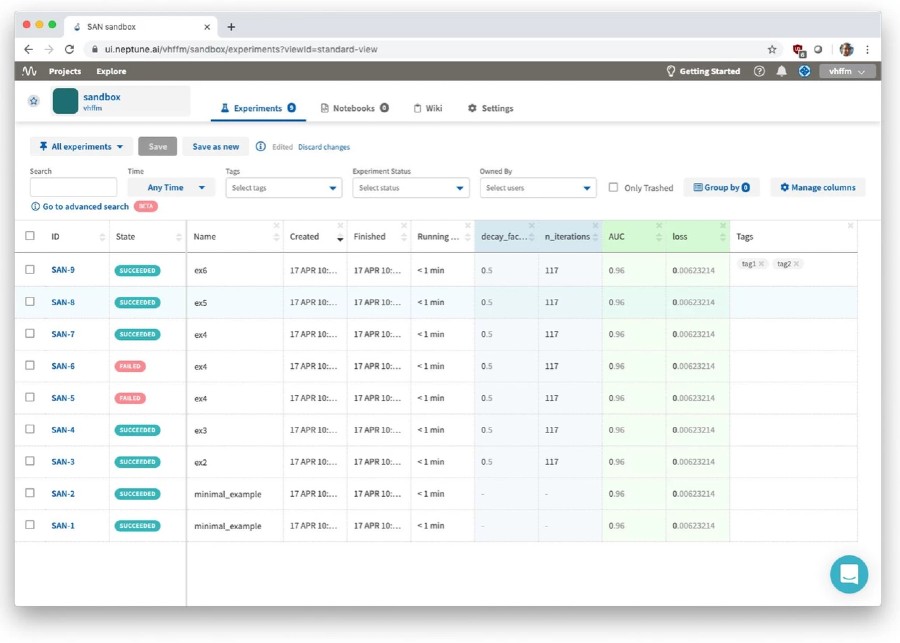
Experiments are tracked by using library hooks to register (model) parameters, evaluation results, and upload artifacts (such as models, hashes of training data, or even code). The library can track hardware usage and experiment progress.
The results can be analyzed and compared on a website. There are also collaborative options. Neptune has integrations with Jupyter notebooks, various ML libraries, visualizers (HiFlow, TensorBoard), other trackers (MLFlow), and external offerings (Amazon Sagemaker). They provide an API to query results from experiment. This can be used to feed CI/CD pipelines for model deployment.
Quickstart:
$ conda create --name neptune python=3.6
$ conda activate neptune
$ conda install -c conda-forge neptune-client
$ cd /somewhere
Go to https://ui.neptune.ai
Create Account, Log In, "Getting Started"
MLFlow
MLFlow is an experiment tracker and generic model server. It can be self-hosted.
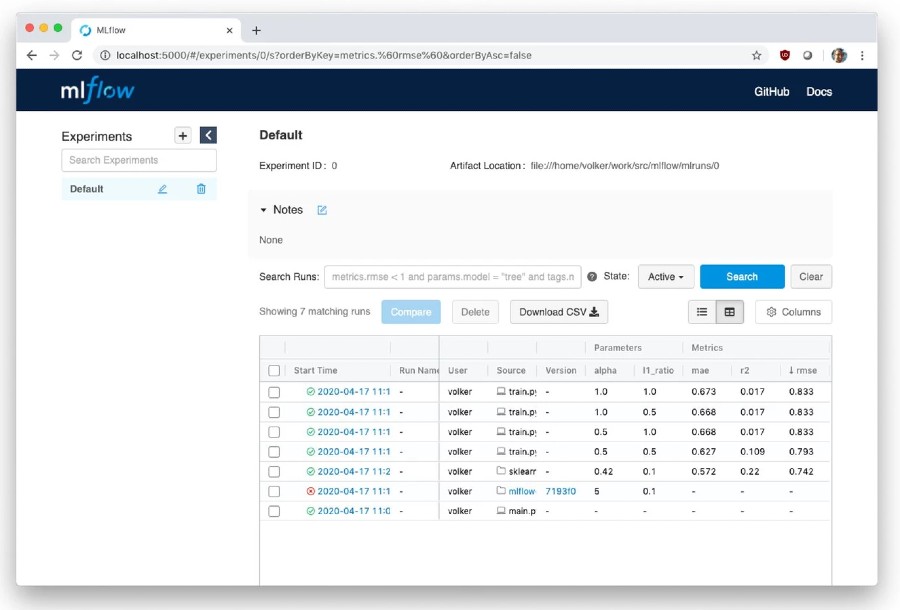

Experiments are tracked by using library hooks to register (model) parameters, evaluation results, and upload artifacts (such as models, hashes of training data, or even code). Artifacts can be logged to local, remote, or cloud storage (S3, GFS, etc).
Results can be analyzed through a web UI and CSV export is available. Models are packaged as a wrapper around the underlying format (Sklearn, XGBoost, Torch, etc). They can be pushed to Spark for batch inference or served through REST. There are CLI, Python, R, Java, and REST APIs for further integration with CI/CD pipelines. Models can be pushed to cloud services (such as SageMaker and AzureML).
$ conda create --name mlflow python=3.6
$ conda activate mlflow
$ conda install -c conda-forge mlflow
$ cd /somewhere
$ mlflow ui
Go to http://localhost:5000
See https://mlflow.org/docs/latest/quickstart.html
Kubeflow
Kubeflow is essentially a self-hosted version of the Google AI platform.
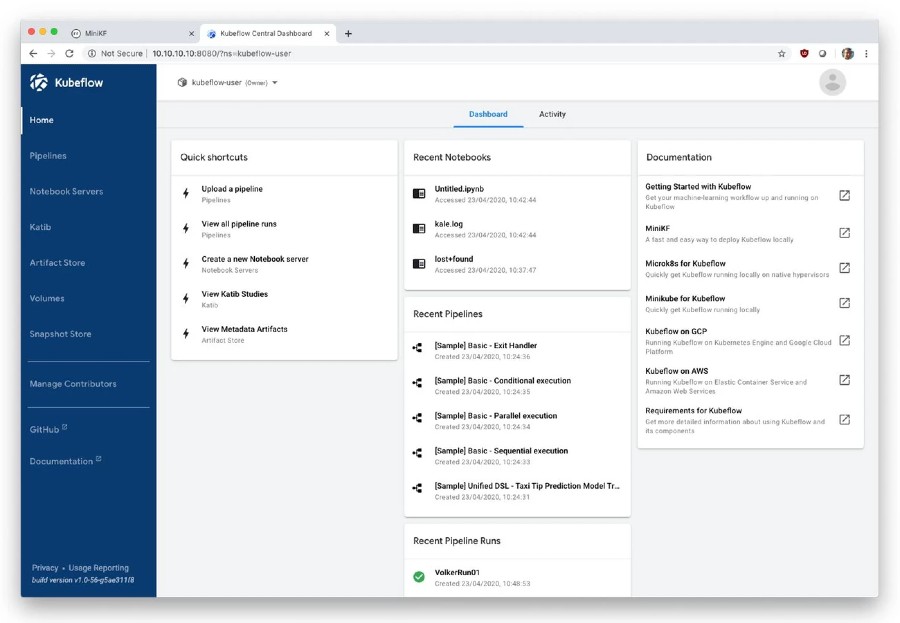
It uses Kubernetes to abstract away infrastructure. Kubeflow can deploy Jupyter notebooks, run pipelines for data processing and model training (scheduled, on-demand), organize runs, archive models and other artifacts, and expose models through endpoints.
Pipelines are compute graphs and are described in Python with a DSL. Their components are wrapped as Docker images. It integrates with GCP so it can elastically scale to the cloud compute and storage (e.g., distributed model training). It also integrates with offerings such as BigQuery or Dataproc. The solution is heavy and complex but enables rapid scale-out. It is especially applicable if infrastructure is already managed through Kubernetes.
$ cd /somewhere
$ vagrant init arrikto/minikf
$ vagrant up
Go to http://10.10.10.10
See https://www.kubeflow.org/docs/started/workstation/getting-started-minikf
Pachyderm
Pachyderm is a versioning system and execution environment for data and processing pipelines. Hosted and self-hosted options exist.
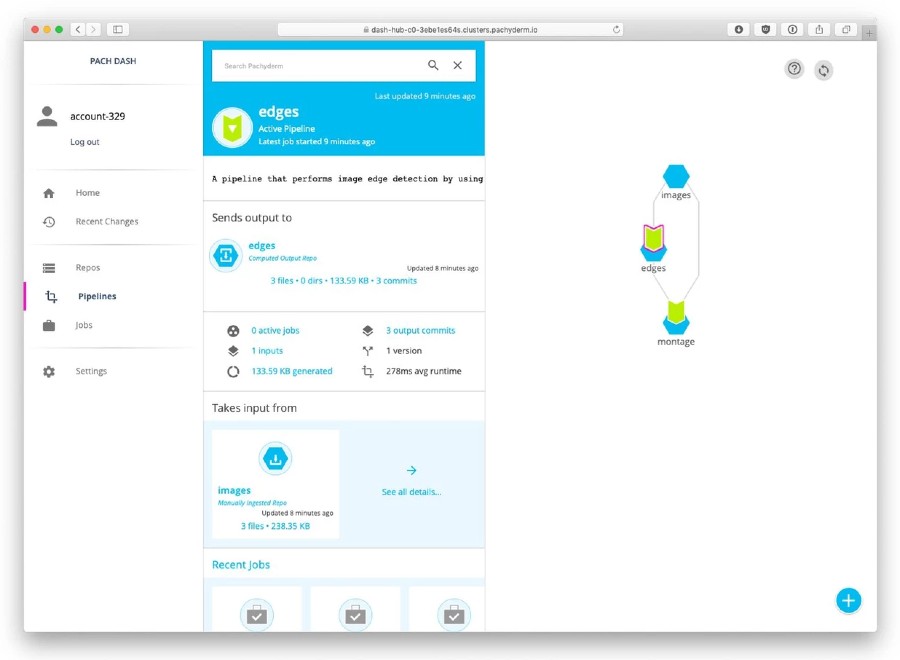
At its core is data provenance. Data is committed to a repository and acted upon by processors in pipelines. The results (data and other artefacts like models) are committed back into a repository.
By design, all use of data is traceable through pipelines. Pipelines are described in JSON and processors are packaged as Docker images. Pachyderm can integrate (but not deploy) Jupyter and can push/pull data from cloud stores (S3, etc). Pachyderm is built on top of Kubernetes, so can easily scale-out and run in various clouds. Self-hosting comes with the usual Kubernetes complexity.
$ cd /somewhere
$ download from (https://github.com/pachyderm/pachyderm/releases)
$ tar xfvz release_filename_linux_amd64.tar.gz
$ pachctl version --client-only
See https://docs.pachyderm.com/latest/pachub/pachub_getting_started
See https://docs.pachyderm.com/latest/getting_started/beginner_tutorial
Hosted One-Stop-Shops
Depending on existing contracts, the maturity of how the AI integration in the organization, an aversion towards running infrastructure, and compliance requirements, some organizations may prefer integrated offerings from large vendors. Solutions include Dataiku, Amazon SageMaker, Azure Machine Learning, and Google AI Platform.
Conclusion and Recommendations
To aid companies in their uptake of AI and data-driven improvements, we outlined the key steps in going from concept to deployment. Within practical applications of this framework, the biggest challenge companies face is in operationalizing AI. To help operationalizing, we have described four (representative) focused technologies. As distinguishing elements, they focus on experiment tracking, infrastructure, and data provenance. Within bounds, most can be built upon to provide other elements. We have also listed (without evaluating), end-to-end data science and AI platforms that contain the entire workflow. Depending on regulations, risk, and maturity, organization may find such solutions preferable.
The following illustration shows recommendations on technical steps companies can follow to shorten the time from concept to impact.

Just Getting Started. If you’re just getting started, tracking experiments and archiving models is a great low-hanging fruit to tackle. Once you see value, you can easily move on to your own or external CI/CD pipelines. Try Neptune or MLFlow.
ScaleUp on Google. If you anticipate to rapidly scale, already use Kubernetes, have complex models, are integrated with the Google Cloud Platform (GCP), and already have mature models and pipelines, you may benefit from integrating everything. Try Kubeflow. Beware – this is a complex solution with significant operational costs.
Containers and Provenance. If you don’t need the full infrastructure management and deep integration into GCP, but still want pipelines with components packaged in containers, you may find a solution that puts emphasizes data provenance interesting. Try Pachyderm. Beware – the self-hosted version of Pachyderm depends on Kubernetes.
Hosted One-Stop Shop. If you have tried a few things, built experience, want to deploy models and keep track of data, but don’t want to touch infrastructure, large vendors with end-to-end solutions and service contracts may be the best way forward. Try Dataiku, SageMaker, AzureML, or Google AI Platform.
Remain Undecided. If you don’t really know where you are and how to proceed, keep it simple. Try Neptune or MLFlow.
This article was first published on the Sintef Smart Data Research Blog. Work was financed by the Energytics project, which is contributing to improving electricity distribution through data-driven techniques.










Comments
No comments yet. Be the first to comment!