


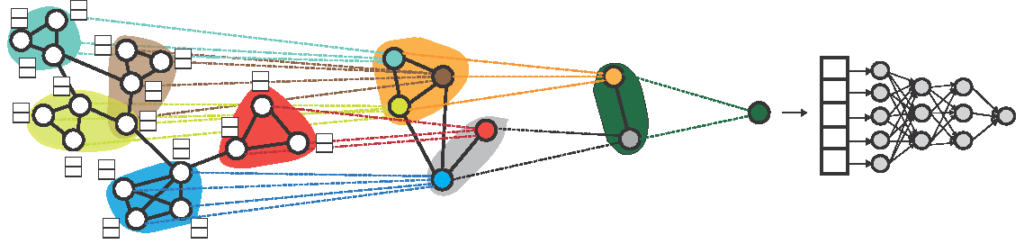
At SINTEF, the Analytics & Artificial intelligence group is collaborating with the Biotechnolocy & Nanomedicine group to work towards this goal, using laboratory experiments, and AI models called Graph Neural Networks (GNNs).
Fragrant, toxic, and anti-viral chemicals
Our work focuses on predicting molecular properties using GNNs. By training these networks on datasets like the Leffingwell Odor Dataset and the Tox21 dataset, we’re exploring new ways to understand molceules via a data-driven approach.
- The Leffingwell Odor dataset allows us to develop models that can “smell” molecules, predicting their olfactory properties.
- The Tox21 dataset enables us to predict toxicity, such as endocrine-disrupting chemicals that interfere with hormonal systems and impact reproductive health.
Accelerating drug discovery and saving resources
Beyond predicting smells and toxicity, this research uses GNNs to predict molecular properties, accelerating drug discovery and reducing the reliance on lab experiments, that can be expensive, slow, and in the case of animal studies, also unethical.
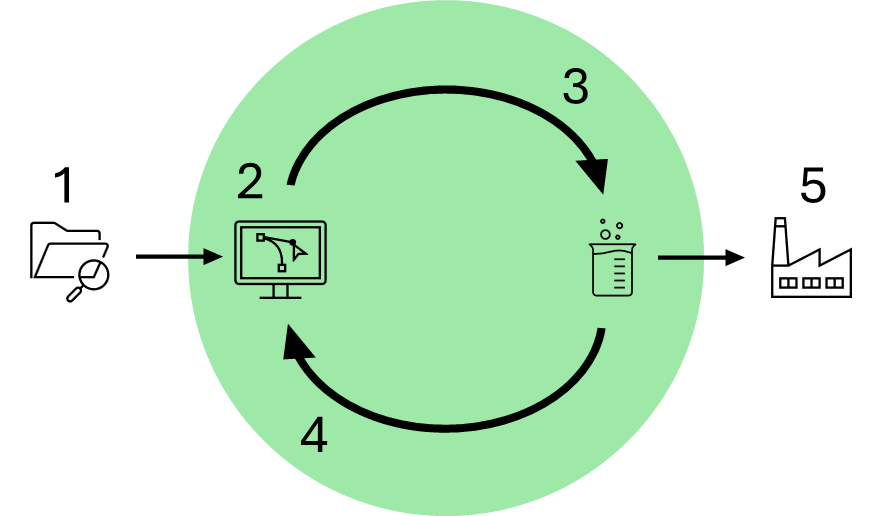
Our approach involves a cyclical process:
- Train a model on existing (offline) data.
- Predict properties of new molecules using the trained model.
- Send the best candidates for validation in the wet lab.
- Update the dataset and refine the model based on lab results.
- Repeat until satisfactory performance is achieved, leading to faster product development and drug discovery.
Preliminary results and future directions
We’ve already seen promising results on data coming from SINTEFs own laboratories, currently reducing screening time by 50%, and aim to increase this to 90%. In addition to GNNs, we plan to explore the use of sequence-based models in the future. These models has achieved significant breakthroughs in natural language processing, and offer an alternative approach by treating the molecular structure as a sequence of letters that can be translated into properties. We are actively seeking partners with interesting data and problems to further expand the applications of our models.
By mimicking the lab with AI, we can reduce the amount of resources needed. This approach has the potential to improve how we discover new drugs and assess chemical safety.








Comments
No comments yet. Be the first to comment!