



AI is starting to change how work gets done in software and scientific computing. Systems are no longer limited to responding to prompts or generating isolated pieces of code. They are increasingly able to plan tasks, use tools, test results and iterate with a degree of autonomy. The shift from generative AI to agentic AI is a true change in kind, and it is accelerating fast.
At SINTEF AgentLab, we have been testing what these developments enable in practice. We are experimenting with agentic coding in our own software projects, building agentic interfaces to scientific modeling tools, and exploring how similar approaches can be used in new application areas. In this post, we share what we have learned so far, why we think it matters, and where we see the greatest opportunities.
From generation to orchestration: what makes agentic AI different
Most people know AI as something you prompt to get a result: a piece of text, some code, an image, or an answer. Tools like ChatGPT and Microsoft Copilot are the obvious examples. They can be very useful, but the interaction is still largely turn-based. The model produces an output, and the human has to judge it, revise the prompt, test the result, and decide what to do next.
Agentic AI changes that pattern. Instead of producing one answer and stopping there, an agent can break a task into steps, use tools, inspect intermediate results, and adapt its next action accordingly. It continues until the task is completed, or until it runs into a problem it cannot resolve.
The underlying idea is not new. What has changed is that current models are much better at handling longer sequences of actions in a way that is more useful in practice. They are better at structuring tasks, keeping track of progress, using feedback, and recognizing at least some forms of failure.
That also changes the role of the human. Rather than carrying out each step directly, the human defines the objective, sets constraints, and evaluates the result. The work is not removed from human control, but the control shifts upward: away from step-by-step execution and toward goals, guardrails, and review.
The pace of change is faster than most organizations realize
Agentic systems have improved markedly over the past year, and much of this progress is easy to miss if you are not testing the tools yourself. Figure 1, based on benchmarks from METR, gives one way of seeing the shift. It tracks the complexity of software tasks that AI models can complete reliably, expressed in terms of how long the same task would take a human expert.
Since 2024, that task horizon has increased steeply. In some cases, tasks that would take a domain expert a full working day can now be completed correctly by an AI agent in less than an hour. At the same time, it is important not to overread the benchmark. The tasks in the figure top out at around 12 hours, and standardized evaluations do not capture the full range of work that matters in scientific software.
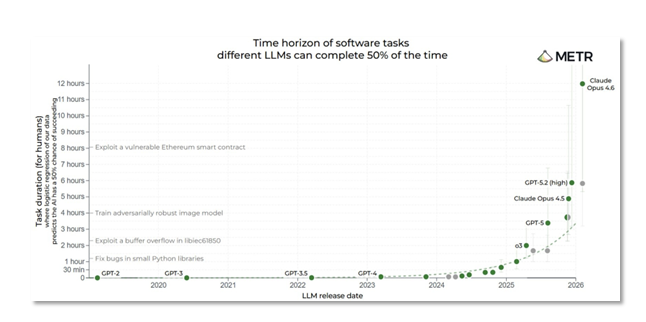
Figure 1. The growing task horizon of AI models. The y-axis shows the time a human expert would need for the same task; the x-axis shows LLM release date. The steep rise from 2024 onward is clear. Source: metr.org/time-horizons
In our own projects, several of the examples we discuss below would likely have taken a skilled developer far longer to build from scratch. That suggests the practical ceiling for well-defined scientific tasks may already be higher than current benchmarks are able to show.
This matters because it changes where value sits in software. When code becomes easier and less expensive to produce, baseline functionality becomes less distinctive and is no longer a differentiator. What matters more is domain expertise, curated data, established workflows, and the judgment needed to frame the right problem and evaluate the result.
Vibe coding vs. agentic coding: not the same thing
It is easy to treat all AI-assisted coding as roughly the same. In practice, it is not. There is an important difference between what is often called “vibe coding” and what we would describe as agentic coding.
Vibe coding is largely prompt-driven and improvisational. The developer asks for something, accepts what the model produces, perhaps tests it informally, and moves on. That can be useful for quick prototypes, experiments, or throwaway scripts. But it is not, by itself, a dependable route to production-quality software.
Agentic coding works differently. The agent operates toward a defined objective by planning, executing, testing, and revising its approach. It works in loops rather than one prompt at a time, and it checks its output against explicit or inferred criteria before declaring success. The human defines the task and reviews the result but does not need to direct every step of the process.
We are also not just talking about better autocomplete. What matters here is the emergence of a more structured development process, one that can in many cases produce surprisingly robust results, even on complex and fairly open-ended tasks. One thing that has repeatedly struck us is the agent’s ability to come up with useful tests and success criteria on its own, and to refine them as it builds a better understanding of the problem.
It is also worth noting that agentic AI does not have to mean one agent working alone. More complex tasks can be split across several specialized agents with different roles. One might gather context and prior work, another breaks the task into steps, another implements and runs code, and another verifies the result and documents what was done. In that setting, the human still remains in control, but from a higher level.
What SINTEF has learned from agentic coding in practice
We have been testing these tools across a broad range of real development tasks. The examples below include production codebases, advanced numerical algorithms, computational geometry, domain-specific simulators, and rapid prototyping. We also include an example of how agents can be used as an interface to advanced modelling tools. Taken together, they give a clearer picture of what agentic AI can already do in scientific software and modelling practice.
Refactoring the linear solver integration in a production reservoir simulator
OPM Flow is an open-source C++ reservoir simulator used operationally on the Norwegian Continental Shelf. It has been developed over more than 15 years through a large multi-organizational collaboration involving Equinor, NORCE, SINTEF, TNO, and others. The codebase contains roughly half a million lines of code. In other words, this is a large production codebase, not a demo or research prototype. That makes it a highly relevant setting for evaluating how agentic coding performs in real software development.
The task was to integrate a new linear solver representation. That involved renaming and restructuring key classes, introducing a new preconditioner factory, adding GPU-forward design patterns to support future acceleration, and making coordinated changes across 20 files, all without changing the simulator’s behavior. For an experienced maintainer familiar with the codebase, this would normally be a substantial piece of work and not without risk.
We developed the plan together with the agent, reviewed it carefully, and then let it carry out the implementation. The full task was completed and validated within 30 minutes, without errors. Figure 2 shows the agent’s workspace during planning and implementation: on the left, the integration plan and target architecture; on the right, later implementation steps, the GPU-forward design, and the completed task list.
This example does not make the expert less important. For such an invasive task in a production codebase, close review and domain judgment remain essential. What changes is the nature of the work: the expert spends less time on manual implementation and more time on architecture, design patterns, and evaluating alternatives. That makes it possible to explore more options, which can lead to better design decisions and higher code quality without losing the deeper understanding that comes from staying closely involved. Review changes as well. The expert does not need to inspect every edit line by line to add value. More effort can instead go into checking that the implementation matches the intended architecture and satisfies the relevant constraints and validation criteria.
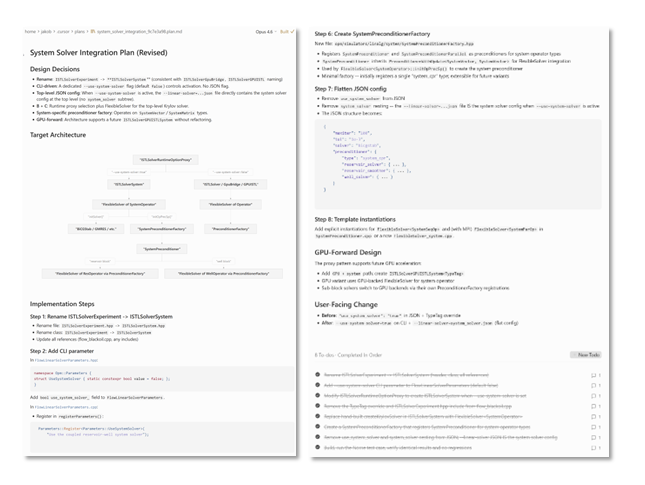
Figure 2. The agent’s workspace during planning and implementation of the OPM Flow refactoring task. On the left is the proposed integration plan and target architecture; on the right are later implementation steps, design notes, and the completed task list. The figure shows that the agent is not just generating code, but working through a structured sequence of planning, execution, and verification.
A route planner with an intuitive interface, built in a weekend
We also tested how far agentic coding could take us in building a small route-planning application from scratch. The result was a simple but functional VRP tool with a live map view, interactive order management, the ability to recompute routes, and simulation playback, all built in a short time with a handful of direct instructions.
This was not Spider, SINTEF’s long-developed vehicle-routing solver, nor was it intended to be. Spider has been developed over three decades and is embedded in commercial logistics systems used daily across the Nordic countries. What we built was much simpler: a lightweight route planner with an intuitive graphical interface showcasing the potential of the technology.
That said, our long experience with Spider mattered a great deal. It meant we knew what to ask for, what a sensible workflow should look like, and how to evaluate whether the generated system was actually useful. That domain knowledge was a large part of why the result worked as well as it did.
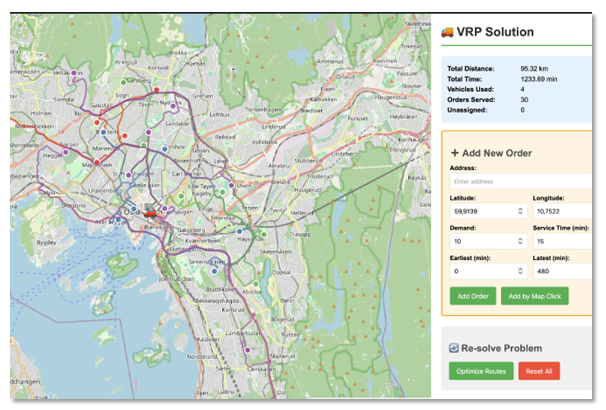
Figure 3. A simple route-planning demo built in a day. The interface shows computed vehicle routes in the Oslo region, with 30 orders served by 4 vehicles. Orders can be added interactively and the solution re-optimized on demand.
Computational geometry: close collaboration and careful iteration
Over the course of a week, alongside normal work, one of us developed a set of advanced computational geometry tools for grid processing in the Jutul family of subsurface flow simulators. The work included generating cut-cell grids in 3D from rectangular and corner-point grid formats used in the subsurface community, gluing non-conformal meshes with planar faces, implementing local grid refinement, and embedding meshes into other meshes. Figure 4 shows two examples of the resulting grids.
This was an important success for us, but it also illustrates something equally important about agentic coding: for difficult algorithmic work, it is rarely a matter of handing over the task and walking away. The human has to stay involved, check the outputs carefully, and expect several rounds of iteration before the result can be trusted.
In this kind of work, code can run without errors and still be geometrically wrong. Catching that, requires domain expertise, visual inspection, and active engagement during the development process. Claude Opus 4.6 was impressive in how well it could plan and execute a large, structured task, but only under careful human oversight.
In the end, we kept the parts of the generated code that seemed valuable enough to maintain and discarded the rest. That is probably the right way to think about this kind of collaboration: not as full automation, but as a way to move faster on hard technical work while keeping expert judgment in the loop.
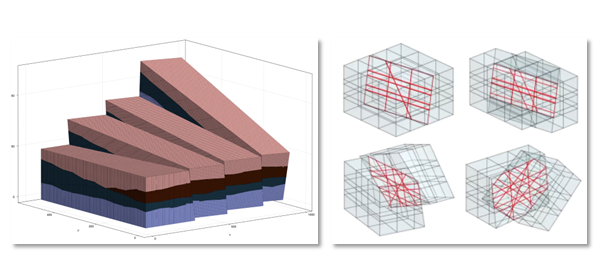
Figure 4. Two examples from the computational geometry work. Left: a corner-point grid with fault blocks and multiple stratigraphic layers, generated from subsurface grid formats. Right: non-conformal mesh gluing, in which a rectangular grid is cut in two and the two halves are displaced and rotated relative to each other along a cut plane. The red lines show the polyhedral intersection geometry that must be computed correctly for the coupling to be valid.
A GUI for a stormwater simulator — and a lesson in working method
SWIM is SINTEF’s open-source Julia package for static modeling and prediction of urban flooding, based on watershed, or spill-point, analysis of terrain topography. Unlike full hydrodynamic simulation, this approach gives near-instant responses, which makes it well suited for interactive exploration of flooding scenarios. That matters in practice for urban planners and climate adaptation researchers, who often need to test many scenarios quickly.
In this case, the immediate context was the SUrbArea project, which aims to reduce societal risk in a changing climate through nature-based solutions in sustainable urban development. The project needed an interface that would allow partner municipalities to work directly with the SWIM software. The graphical user interface (GUI) built with the agent, shown in Figure 5, adds a full 3D interactive interface with terrain visualization, configurable surface layers, object layers for buildings and roads, drainage network display, and simulation controls.
This case also taught us something about how to work with an agent. The GUI was developed through very tight human control, never giving the agent more than could be reviewed comfortably in one step. That led to high token use and, based on what we saw in other projects, was probably both more expensive and less efficient than necessary.
Across several projects, we have generally seen better results when the task is defined clearly at a higher level and the agent is given more room to plan and execute. That is where its ability to reason about structure, propose sensible intermediate steps, and come up with useful validation criteria seems to matter most.
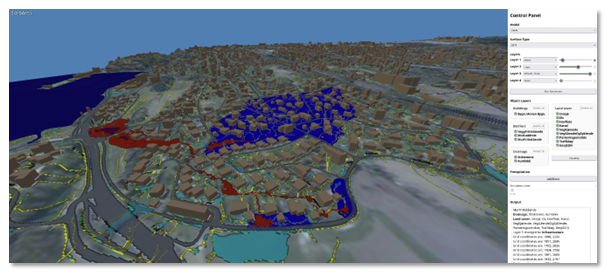
Figure 5. A 3D interactive GUI for SINTEF’s SWIM tool, shown here for the area around Hvalstad station in Asker municipality. The interface visualizes how terrain and infrastructure shape drainage and water accumulation during heavy rainfall, and includes controls for terrain layers, object layers, and simulation settings. The data used in this example was originally obtained from Kartverket (the Norwegian Mapping Authority).
How quickly new tools can now be built
The next two examples were built for a demo we were asked to prepare, with little more than a day available. They were developed side by side on a single workstation. The short timeline was intentional: part of what we wanted to test was how quickly useful new tools could be assembled.
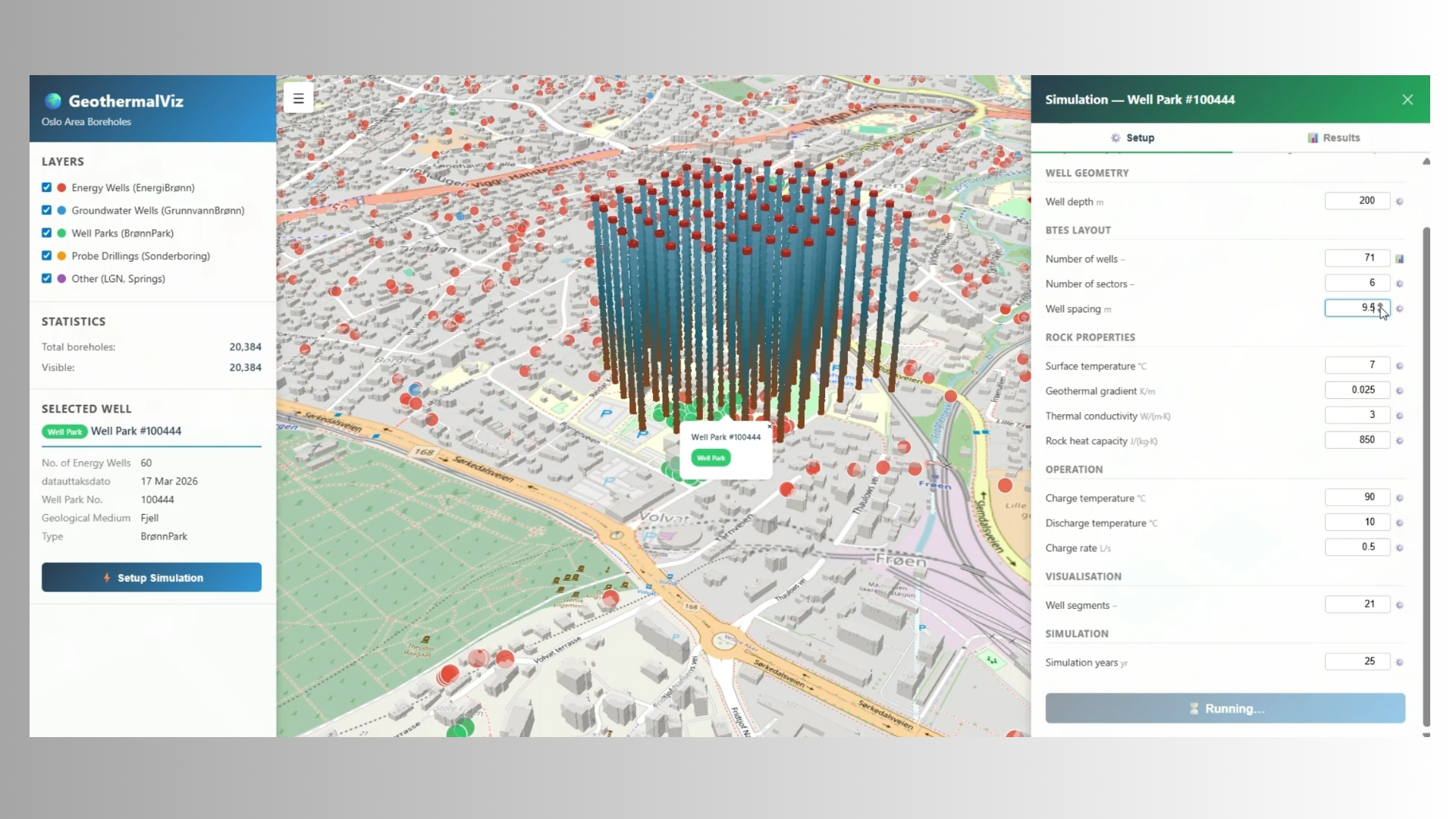
The first tool was built to show how quickly a useful interactive front-end can be created around an existing scientific software product. In this case, that product was Fimbul.jl, SINTEF’s open-source Julia package for simulation and analysis of geothermal reservoirs and thermal energy storage systems. The tool uses openly available borehole data from the Norwegian Geological Survey (NGU) and visualizes all available boreholes in a selected region in an interactive 3D map. It lets users explore and reconfigure geothermal well designs while also giving them a better understanding of the data used as input to the simulator. Figure 6 shows an example in which a 60-well park was reconfigured and used to set up a simulation.
The point was to showcase how modelling tools like Fimbul can be made more accessible through a graphical interface and direct coupling to open public data. The current coupling to Fimbul works for simple setups, while fuller integration is still ongoing. This example also shows one way agentic AI can be used responsibly in scientific software: the agent builds the interface layer, connecting data sources, visualizations, and user interaction, while the actual computations are still carried out by simulators we have developed and validated over many years. That makes it easier for domain experts such as geologists and energy planners to work directly with the simulator, without having to learn its internal API.
The second example was very different. On 16 March 2025, a wildfire broke out at Sukkertoppen in Ålesund, leading to the evacuation of 450 residents. That same day, we began building a simple wildfire simulation tool. This was outside our usual application areas, which made it a useful test of how far an agent could get from a broad problem description.
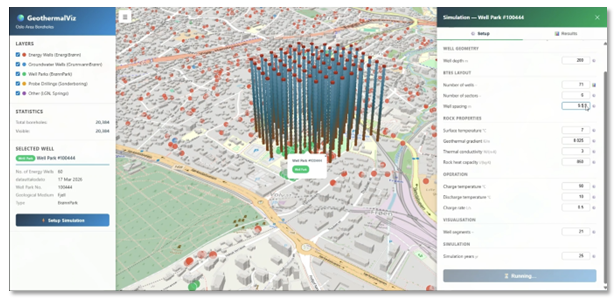
Figure 6. An interactive tool for geothermal simulation that combines open borehole data from NGU with the Fimbul geothermal simulator. Users can explore existing boreholes, design new configurations, and set up simulations through a graphical interface.
The task was deliberately left open-ended. Rather than specifying a detailed solution, we gave the agent a high-level description of the problem and asked it to find a workable approach. It retrieved scientific literature on cellular automata models for fire spread, identified suitable models, sourced open coastline, land-cover and terrain data, and implemented the simulation in Julia. Figure 7 shows the result.
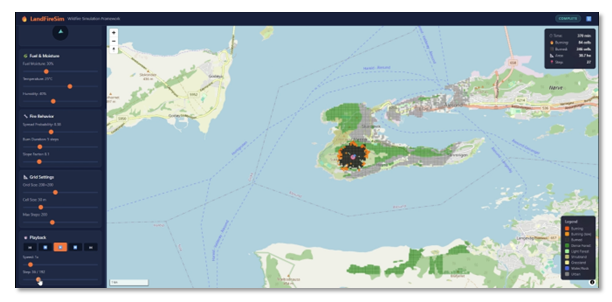
Figure 7. A wildfire simulation tool built in Julia in roughly a day using openly available datasets. The tool can set up simulations for locations worldwide and is shown here for the Sukkertoppen area in Ålesund, where a real wildfire broke out on 16 March 2025. Orange cells are actively burning, black cells have burned, and green cells indicate forest cover.
A disclaimer is needed here. This is only a demo, not a validated tool. Before it could be used operationally, the underlying model would need to be reviewed carefully and validated against documented fire events, the data sources checked for accuracy at the relevant scale, and the model outputs calibrated against observed fire behavior. The point of this experiment is not that the agent produced a ready-to-use simulator in a day, but that it produced a credible starting point, working largely on its own from a high-level description of the problem.
We also completed several other modules and tools. These included a JutulDarcy solver for computing time lines and delineating flow regions in flow diagnostics and a port of the virtual element method from our open-source MRST simulator, a result plotter for OPM Flow, and visualization of flow solutions on multi-segment wells. We mention these only briefly here so that the more demanding examples can receive fuller treatment.
Developing a high-performance AMG solver in Julia
Large-scale simulation of physical processes, whether in subsurface flow, structural mechanics, climate modeling, or battery design, often comes down to solving large systems of linear equations. This is usually one of the most computationally demanding parts of the workflow, and solver performance can determine whether a simulation is practical at all, and at what scale. Algebraic multigrid (AMG) is one of the leading methods for this class of problem, because it can achieve near-optimal complexity across a wide range of applications. For a serious simulation framework, having an efficient AMG implementation is therefore a core capability.
A widely used reference implementation is hypre, developed at Lawrence Livermore National Laboratory over several decades with sustained funding and deep specialist expertise. We asked an agent to develop a corresponding AMG module for our Jutul framework, which forms the common computational basis for our work in reservoir simulation, geothermal energy, batteries, and other domains. The new solver was named Draugr.
The prompt was specific about the architectural choices needed for GPU compatibility, and the process was genuinely collaborative. We supplied our own tests and verification output against a reference implementation, which the agent used to guide its iterations. It is important to be clear about scope here: the module targets scalar problems of the kind that arise in our simulators, and it does not include MPI parallelism, which accounts for a large part of the complexity in hypre. Even with that narrower scope, getting a cross-platform implementation working overnight on CPU, GPU, and Apple Metal, and across Windows, macOS, and Linux, was striking.
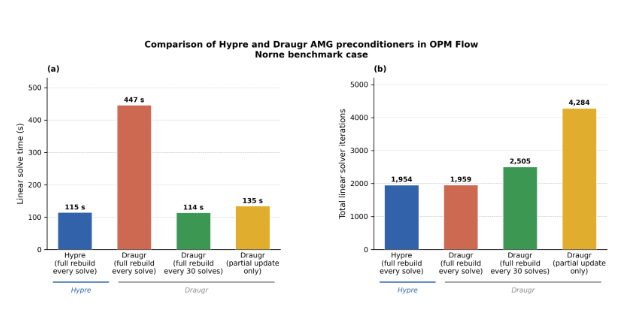
Figure 8. Comparison of the hypre and Draugr AMG preconditioners running in OPM Flow on the Norne benchmark case. (a) Linear solver wall-clock time and (b) total linear solver iterations. Draugr with a full hierarchy rebuild every 30 solves matches hypre in both
The resulting module is encouragingly competitive with hypre on a representative set of test cases. However, hypre still has an advantage in setup time and is marginally faster in some preconditioner applications, while the new module is designed for rapid re-setup, which matters in our simulation workflows. Figure 8 shows a comparison. The benchmark is not fully apples to apples, and further testing is still ongoing, but the result is nonetheless notable: a focused, domain-specific AMG module, competitive on its target problem class, was developed in the course of a single night.
The implementation is largely a port of ideas from hypre, which is permissively licensed. That points to a broader issue. When agents can reproduce algorithms and implementation patterns very quickly, questions of authorship, provenance, and licensing become more important, not less, especially in cases where the original source material may not have permissive terms.
Agents as natural language interfaces to scientific simulators
We are also exploring agentic AI not just for software development, but as an interface to scientific simulators. This is the motivation behind JutulGPT, an LLM agent coupled directly to our JutulDarcy reservoir simulator. The agent accepts natural-language descriptions of simulation scenarios, interprets the user’s intent, generates the necessary code, and validates the result by attempting to run the simulation. When it encounters ambiguities, it asks for clarification. When it detects errors, it iterates and repairs.
This is a different kind of task from ordinary agentic coding. In software development, correctness can often be checked against tests. In simulation model setup, that feedback is weaker: a model can run to completion and still be scientifically wrong. JutulDarcy helps here by enforcing internal consistency checks on conservation, closure relations, and solver convergence, so that a completed run is at least physically admissible. That still does not guarantee that the model matches the user’s full scientific intent, which is why ambiguity handling and human oversight remain important.
Figure 9 shows a simple example: a heterogeneous 3D reservoir model generated from a single paragraph of natural-language description. In this case, the agent was asked to operate in interactive mode, checking back with the user whenever it encountered decisions that would materially affect the model. A fuller account of JutulGPT, including the reasoning behind its design, what we learned, and a discussion of reproducibility and trust, is given in a companion post and our recent arXiv paper.
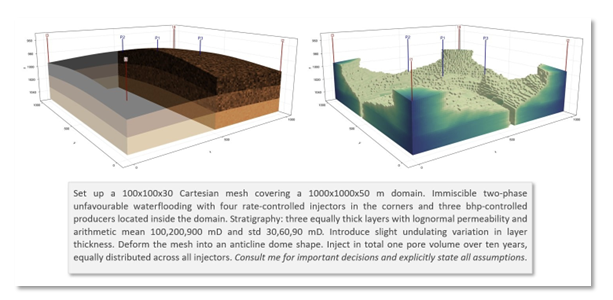
Figure 9. Waterflooding scenario created by JutulGPT from a natural-language prompt. The prompt is shown below the results. The left panel shows the model geometry and heterogeneity; the right panel shows how water has spread through the reservoir after the injected water has reached the producers.
What does this mean in practice
The examples in this post point in two directions at once. They show what agentic AI can already do in software and scientific computing, but they also say something broader about where this technology may matter next, what conditions responsible adoption requires, and what this could mean for researchers, clients, and other knowledge-intensive organizations.
Beyond software: where agentic AI is beginning to take hold
Software is only the first place where agentic AI is becoming hard to ignore. The deeper pattern is that these systems can learn and execute work that follows a recognizable method and can be checked along the way. That applies far beyond programming. Many forms of knowledge work that are often treated as irreducibly human are, in practice, much more procedural than their practitioners like to admit.
This has uncomfortable implications. For work consists of gathering information, applying a learned method, producing an assessment, and revising it against some form of feedback, agents are likely to improve rapidly. In that sense, agentic AI is not only a challenge to routine work. It is also a challenge to professions whose authority rests on methodical expertise.
Responsible adoption requires more than enthusiasm
That does not make the answer “move fast and hope for the best.” The risks are real. Agents can produce plausible but incorrect results, fail silently, and encourage over-delegation if they are used carelessly. In scientific and professional settings, that can have serious consequences. Human accountability does not disappear when an agent is involved. If a result is approved, shipped, or used in decision-making, responsibility still rests with the people and organizations that chose to rely on it.
Responsible adoption therefore requires governance from the start. As implementation becomes less expensive, the quality of the task definition matters more. Vague intent, missing constraints, and underspecified edge cases do not disappear when agents enter the loop; they become more consequential. Results must be reviewable and auditable, permissions must be bounded, and teams must retain enough domain knowledge to question and verify what the agent is doing. Perhaps most importantly, organizations must avoid gradual deskilling: if too much judgment is delegated too early, they may lose the expertise needed to detect when the system is wrong. The goal is not to avoid agentic AI, but to use it in ways that preserve trust, rigor, and accountability.
For researchers and clients
For researchers and organizations like SINTEF, this change may be profound. Agentic AI compresses the distance between idea and result. Literature search, implementation, simulation setup, and analysis will likely all become faster. But that does not remove the need for expertise. It makes it even more important to ask the right question, define the task well, and judge whether results are actually correct and useful. That makes deep domain expertise more important, not less. However, agentic AI also opens a new opportunity: building agentic interfaces around advanced modeling tools so that capabilities developed over many years can be made accessible not only to more domain experts, but also to non-experts, by translating between everyday language and the formal language these systems require.
For clients in industry and the public sector, the same shift creates both an opportunity and a pressure. Bespoke tools, interfaces, and analyses are becoming cheaper and faster to build, making new kinds of solutions feasible. At the same time, organizations that do not develop their own understanding of where and how agentic AI can be applied — meaning systems that can learn and execute structured methods, not just generate text or code — risk being outpaced by those that do. The biggest gains are unlikely to come from individual use alone. They will go to organizations that can identify which parts of their work are structured enough to accelerate, build the expertise needed to direct, verify, and critically assess AI-assisted outputs, and redesign workflows, roles, and interfaces so that agentic systems become part of how the organization actually works.
Meanwhile, at SINTEF AgentLab, we will keep experimenting, keep building, and keep sharing what we learn.
Further reading
The items below are not meant as a formal reference list, but as a selection of papers, articles, and posts we have found useful and thought-provoking in relation to agentic AI.
- Agoda. From implementers to solution architects: why AI makes your specs the new bottleneck — on how AI-assisted software development changes the role of the expert from manual implementation toward architecture, intent, and verification.
- Anthropic. Long-running Claude for scientific computing — on how multi-day agentic coding workflows can be applied to scientific computing tasks, and why progress files, reference implementations, and explicit success criteria matter.
- D. E. Knuth. Claude’s Cycles — a firsthand account from Donald Knuth of working with Claude on a graph-theory problem, and a striking example of how agentic AI is beginning to matter even in advanced mathematical work
- J. Krys. On theoretical physics, AI and human creativity — a thoughtful commentary on recent AI progress in theoretical physics, and what it may imply for creativity, specialization, and scientific judgment.
- L. de Moura. Proof Assistants in the Age of AI — on why formal verification, readable specifications, expressive foundations, and good tooling matter even more when AI is generating proofs, and why verification alone does not remove the human burden of stating the right theorem.
- S. Sado. Can you relicense open source by rewriting it with AI? The chardet 7.0 dispute — a detailed legal and governance-oriented discussion of AI-assisted reimplementation, relicensing, and the authorship and provenance questions that arise when agents are used to rewrite existing software.
- M. Schwarz. Vibe physics: The AI grad student — on guiding Claude through a real theoretical-physics project, and on the difference between impressive autonomous progress and scientifically trustworthy results.
- G. Sivulka. Institutional AI vs individual AI — on why the biggest gains from AI may come not from individual productivity alone, but from redesigning workflows, coordination, and purpose-built tools at the organizational level.
- T. Tao et al. Mathematical exploration and discovery at scale — arXiv paper on AlphaEvolve, tested on 67 mathematical problems, with improvements over the state of the art in several cases.
- A. V. Tobias & A. Wahab. Autonomous “self-driving” laboratories: a review of technology and policy implications — a review of how AI and laboratory automation are being combined to close the loop between hypothesis, experiment, and analysis in chemistry, materials science, and the biological sciences.







Comments
No comments yet. Be the first to comment!